Blendemoji
An interactive Plugin
2020.09 - 2020.11
This is a research project advised by Professor Brian A. Barsky at University of California, Berkeley
Tools: Blender, Python, OpenCV
Table of Contents
Project Overview
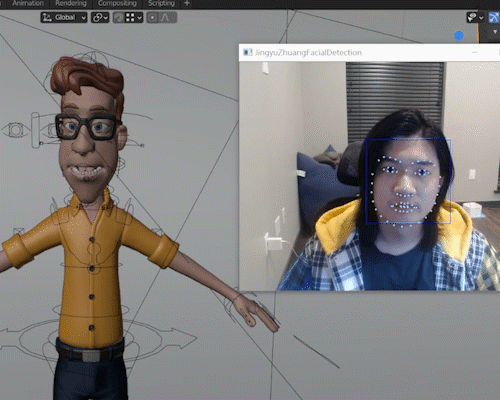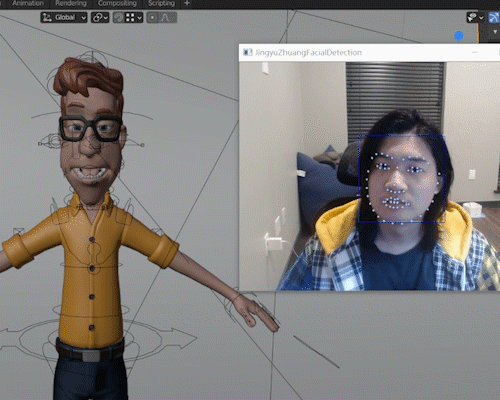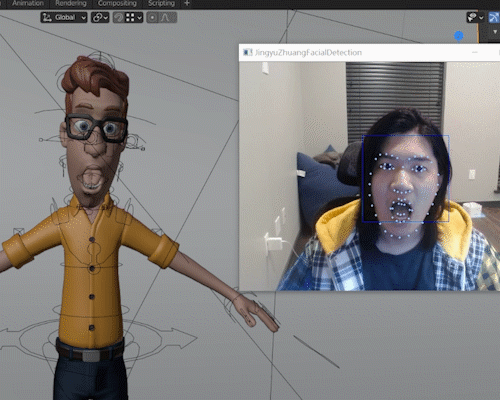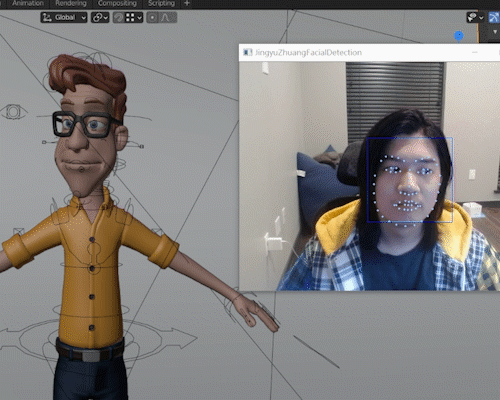
Blendemoji, used on Vincent, an Opensource Blender Model available on Blender Cloud
Blendemoji is a Python scripted plugin for Blender which reads the user’s facial expression through Webcam and simulates it on a 3d rigged model.
Technical Overview
The idea is simple:
Extracting data from the user’s face input -> interpret the data and apply it onto the model.
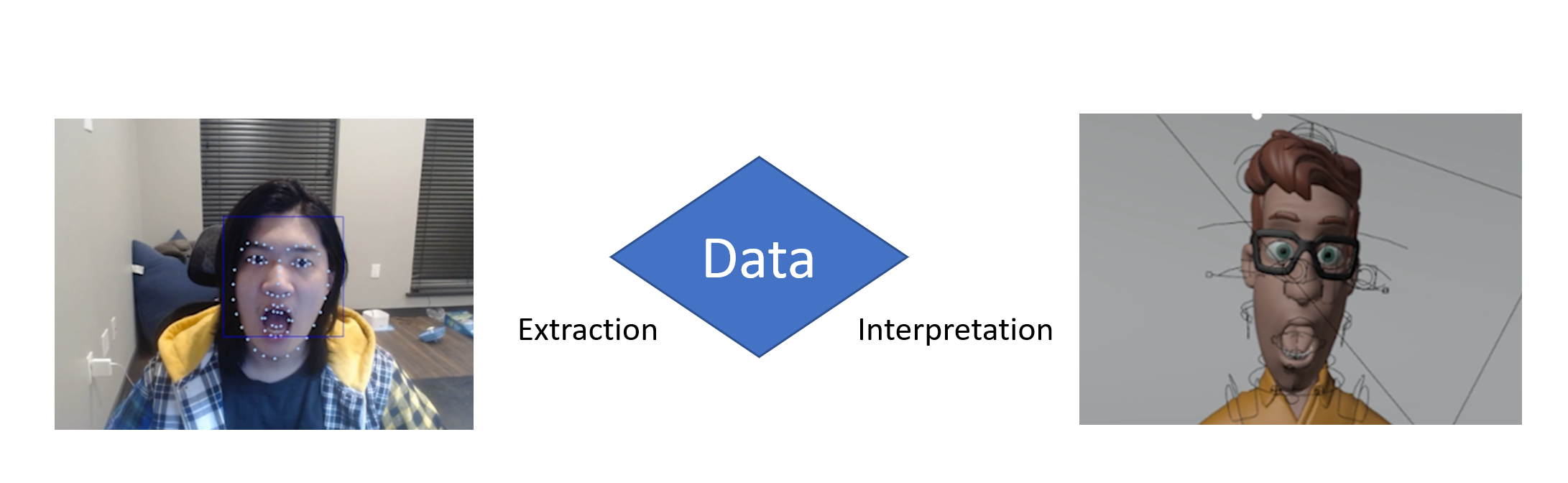
Haar Cascade
I start by recognizing rectangular faces in our webcam picture.
Haar Cascade is a machine learning object detection algorithm used to identify objects in an image or video and based on the concept of features proposed by Paul Viola and Michael Jones in their paper “Rapid Object Detection using a Boosted Cascade of Simple Features” in 2001.
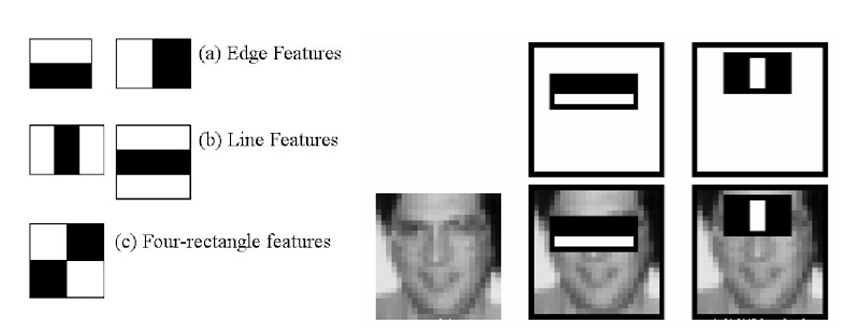
The picture on the right demonstrate the idea. Top row shows two good features. The first feature selected seems to focus on the property that the region of the eyes is often darker than the region of the nose and cheeks. The second feature selected relies on the property that the eyes are darker than the bridge of the nose.
In OpenCV library the algorithm applied by calling function void detectMultiScale()
void cv::CascadeClassifier::detectMultiScale
( InputArray image,
std::vector< Rect > & objects,
double scaleFactor = 1.1,
int minNeighbors = 3,
int flags = 0,
Size minSize = Size(),
Size maxSize = Size()
)
| Parameters | Explanation |
|---|---|
| image | Matrix of the type CV_8U containing an image where objects are detected. |
| objects | Vector of rectangles where each rectangle contains the detected object, the rectangles may be partially outside the original image. |
| scaleFactor | Parameter specifying how much the image size is reduced at each image scale. |
| minNeighbors | Parameter specifying how many neighbors each candidate rectangle should have to retain it. |
| flags | Parameter with the same meaning for an old cascade as in the function cvHaarDetectObjects. It is not used for a new cascade. |
| minSize | Minimum possible object size. Objects smaller than that are ignored. |
| maxSize | Maximum possible object size. Objects larger than that are ignored. If maxSize == minSize model is evaluated on single scale. |
Facial Landmark API
with my detected landmark feature. I used Facial Landmark API to further recognize different facial components.
Facial Landmark API uses “Active Appearance Models” algorithm to match statistical models of appearance to images.
Active Appearance Models Algorithm is a method of matching statistical models of appearance to images, developed by Timothy F. Cootes, Gareth J. Edwards, and Christopher J. Taylor. (Their Paper)[https://people.eecs.berkeley.edu/~efros/courses/AP06/Papers/cootes-pami-01.pdf]
To detect landmarks we use function virtual bool cv::face::Facemark::fit()
virtual bool cv::face::Facemark::fit (
InputArray image,
InputArray faces,
OutputArrayOfArrays landmarks
)
| Parameters | Explanation |
|---|---|
| image | Input image. |
| faces | Output of the function which represent region of interest of the detected faces. Each face is stored in cv::Rect container. |
| landmarks | The detected landmark points for each faces. |
Now we have our data extracted, let’s try to interpret data and apply it on our models.
Perspective-n-Point
My data extraction happens on a 2D plane image, the next step is to convert it into 3D space.
Perspective-n-Point is the problem of estimating the pose of a calibrated camera given a set of n 3D points in the world and their corresponding 2D projections in the image. The camera pose consists of 6 degrees-of-freedom (DOF) which are made up of the rotation (roll, pitch, and yaw) and 3D translation.
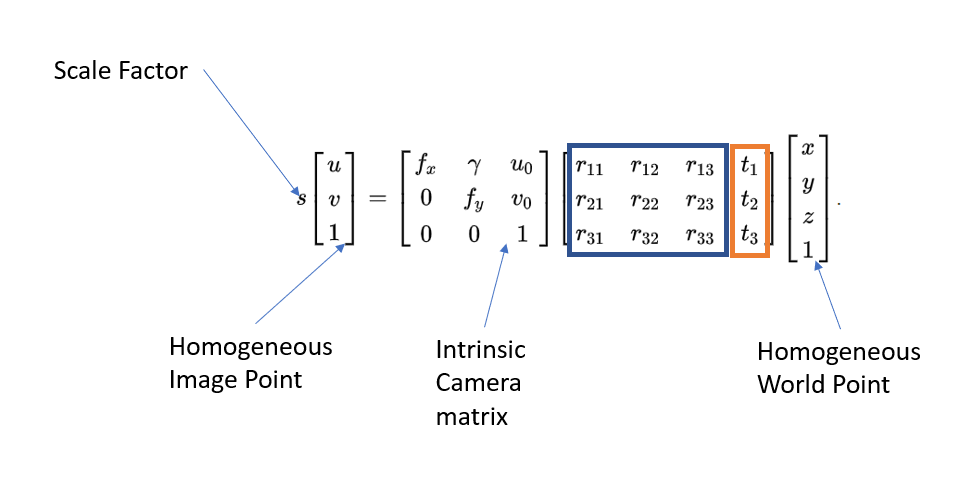
Let’s break down the equation:
S is the scale factor for the image point
Homogeneous Image Point: the point on the 2D image (In this case it’s the coordinate of user’s facial component on the image)
Intrinsic Camera Matrix: the intrinsic parameters of our camera (In this case it’s the webcam, the physical pinhole camera). f here is the focal length, u v is the coordinate of principle points which are commonly zero. Gamma is the skew coefficient which is also commonly zero.
Homogeneous World Point: the point on the 3D model (In this case it’s the coordinate of the specific bone corresponding to the facial component)
And that leaves us with the matrix on the middle, the [R T] matrix. Which can be broke down as 3D Rotation and Translation which can be applied onto the model.
bool cv::solvePnP (
InputArray objectPoints,
InputArray imagePoints,
InputArray cameraMatrix,
InputArray distCoeffs,
OutputArray rvec,
OutputArray tvec,
bool useExtrinsicGuess = false,
int flags = SOLVEPNP_ITERATIVE
)
| Parameters | Explanation |
|---|---|
| objectPoints | Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel, where N is the number of points. vector |
| imagePoints | Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel, where N is the number of points. vector |
| cameraMatrix | Input camera intrinsic matrix A. |
| distCoeffs | Input vector of distortion coefficients (k1,k2,p1,p2[,k3[,k4,k5,k6[,s1,s2,s3,s4[,τx,τy]]]]) of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed. |
| rvec | Output rotation vector (see Rodrigues ) that, together with tvec, brings points from the model coordinate system to the camera coordinate system. |
| tvec | Output translation vector. |
| useExtrinsicGuess | Parameter used for SOLVEPNP_ITERATIVE. If true (1), the function uses the provided rvec and tvec values as initial approximations of the rotation and translation vectors, respectively, and further optimizes them. |
| flags | Method for solving a PnP problem. |
And… Done!
What Could Go from Here
I personally enjoyed the whole process developing this project. And as a game designer I would really love to see what would happen if we can gamify this. Because it’s such a unique way of human computer interaction. And it reminds me of the game Ring Fit Adventure which a strap on players’ thig to have body movement as input. The game was created to encourage people working out their bodies.
If the same design philosophy can be applied here, we might create a game to excourage people working out their facial muscles as a way to prevent facial paralysis, etc.